Hey Reham! Let’s start by telling our readers a little bit about you and your role with Toronto Open Data.
I’m Reham Youssef. I’m the Marketing and Communications Lead for the open data team, and I’ve been with the City for over fifteen years but in the last ten years, I’ve really been focusing in on open data.
Tell us about the project you’re currently working on.
Sure. At open data, we always want to know: what do users want? In the past we would accept dataset requests through email and twitter on an ad-hoc basis. We didn’t really have a concise way of gathering data from the public on what they want when it comes to open data and we’ve been trying to establish different criteria that will help us evaluate and prioritize dataset releases.
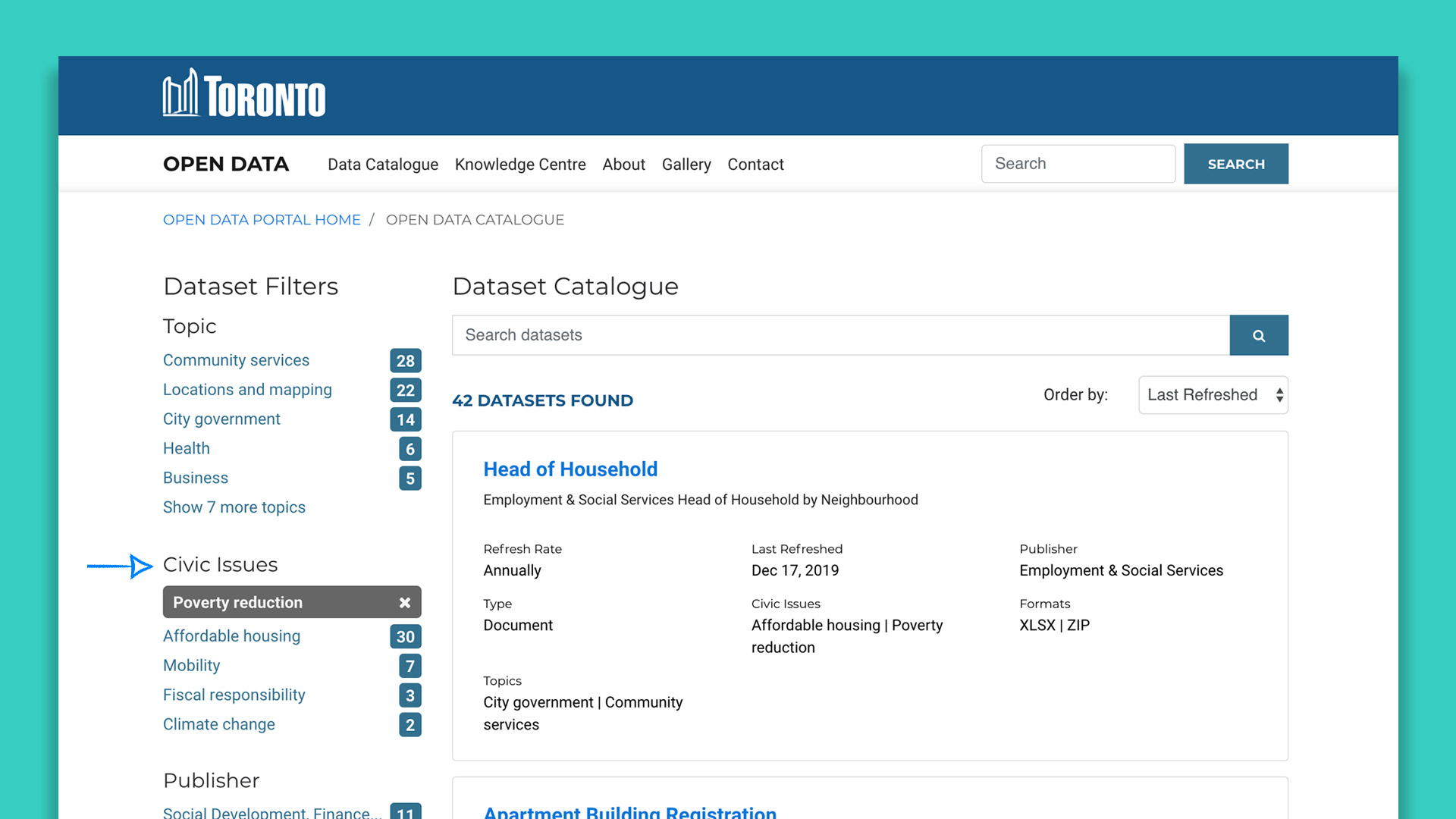
The Mayor recently announced three new city directives. We took that list and identified two more: climate change, which is an important global issue right now, and poverty reduction, which we heard as a consistent theme from the civic tech community. This gave us a list of five total civic issues we wanted to prioritize dataset releases around: affordable housing, poverty reduction, fiscal responsibility, climate change, and mobility. We’re now considering the impact of these civic issues in determining what we release next.
Why is it important to know how to prioritize what datasets get released?
It’s just a better way to understand data requests, and we wanted to make sure that incoming data requests align as much as possible with these priorities.
We can’t release everything at once. Unfortunately we have limited resources and (wo)manpower, and we also have to work with 44 different City divisions. As you can imagine, there are numerous units within the individual divisions that are responsible for data.
When we prioritize data, we link it to the city priorities which you can then narrow down to 5 to 10 divisions, which makes it much easier for us to discuss with those divisions instead of all 44. Often times it’s tricky to ask for data when we don’t even know how or where it exists, let alone if it exists in the first place. So we decided to focus in on the most important things for the city. We want to establish a consensus on what users want, and specifically go after that data.
Great! So you started by developing a survey that would be filled out by users to inform what civic issues and datasets they wanted. How did that go?
Well, when we first went out the door with the initial civic issues survey, we unfortunately didn’t get what we were looking for the first time.
Why is that?
There were just too many questions, and we were asking for too much detail at the time. People didn’t understand how to respond. We really wanted people to tell us as much as possible, right down to the data attributes, and exactly what they wanted. We started to see that while people know they want to solve problems like affordable housing, they don’t always necessarily know what data they need to address that problem.
So what did you do when you found that users weren’t filling out the civic issues survey as expected?
After a month, we took the survey down and switched things around. That’s how we got to the second questionnaire, where we simplified it down to 3 simple questions. The wording had to change for people to think differently, and asking people what they wanted and what they wanted to do with the data was the main driver. The reason we asked for what they will do with the data is because of a fun little algorithm we created that I’ll go into detail later.
What was the result?
Unexpectedly, we were overwhelmed with responses! 875 in total. We received enough information from our users the second time around that we could plug right into the prioritization framework. This gave each dataset request a score as well as informed us as to how many people were asking for the same data in different words.
Can you tell our readers a little bit about the prioritization framework?
The prioritization framework was developed by the open data team as a way to assess and prioritize upcoming dataset releases. The algorithm was developed by Ryan Garnett, who manages the open data team as well as the geospatial competency center (
Editor’s note: Ryan writes frequently for the Open Data Knowledge Center; you can read his articles here) in the form of a dynamic spreadsheet.
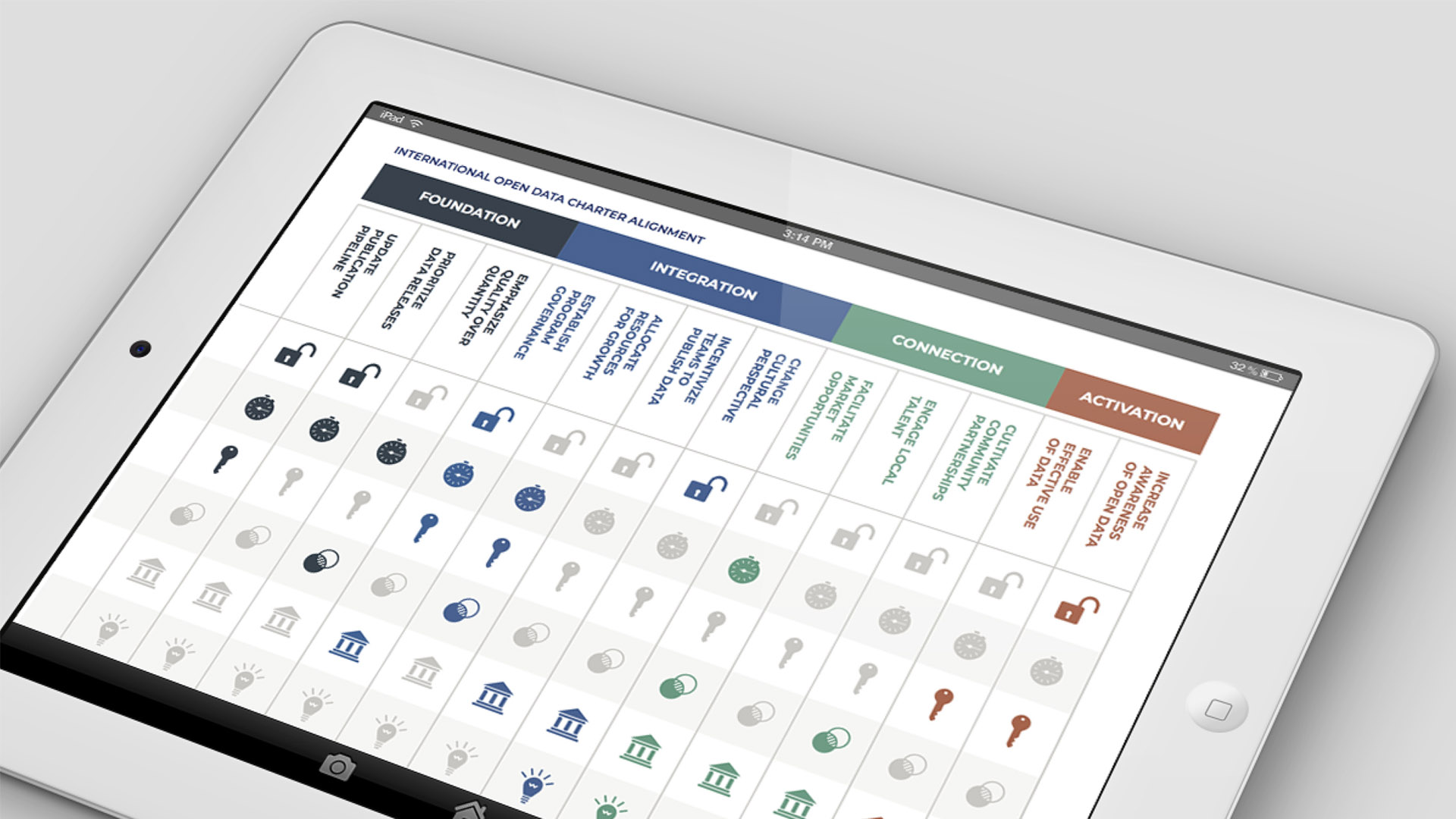
The framework focuses on five outputs. Each output is given a specific score. The algorithm applies a weighting to all these scores and then outputs an overall ranking.
The primary assessment metrics are:
Source
Is the data in a database somewhere or is it in a spreadsheet on someone’s desktop?
Civic Issue
A dataset request that isn’t related to one of the five main civic issues would receive a lower score than one that does.
Requester
Who requested the dataset? Is it requested by council or a member of the public? Different requesters are given different scoring.
Output
What will it be used for? Education? Media? Government city report? Is it for research? Will it be used to create a by-product, like an app?
So the framework lets us figure out where the priority lies for every request. The higher the number, the more we will focus in on getting that data from the appropriate division or unit.
Do you think the scores will be made public anytime soon?
They’re already public but they aren’t presently linked to the prioritization framework! We’ve got a few more things to do first. We’re reviewing all of our requests, separating one single request perhaps into two or more data requests, manually tagging them with topics or themes and separating them out by civic issue. We’re actively working on releasing that data to the public in a raw format. It’ll contain every single request with the requester listed.
What is the benefit of releasing that data to the public?
It’ll be our first actual open dataset from open data.
Data about the data!
Yes, exactly. This will give people the opportunity to take a look and play around with the data. We’re going to analyze the data and figure out how many requests there are based on tags. We’ll plug each one into the framework, then come up with a score that we then report back to the senior management team (SMT) or appropriate division. That we hope to release soon, publically, and ultimately this is how we want to report back.
That seems fairly well-aligned with the mandate of open data, which includes transparency as well as data-informed decision making.
That’s right.
So what are your next steps as this seems like a fairly mammoth undertaking.
We’re going to clean the data for the release. My personal next steps are to perform a little bit of an analysis so we can have a cool data story to report back with. I’m not a data scientist, so I’ve never worked with so many sources before, but I’m excited to venture off and try this. I want to have some sort of summary story that tells us the total number of requests, unique tags, and breakdown of civic issues.
Ultimately we want users to understand how we took nearly a thousand requests and categorized them with tags and top civic issues.
Thank you, Reham, for explaining the open data civic issues campaign and prioritization framework. We welcome reader comments and questions to opendata@toronto.ca.


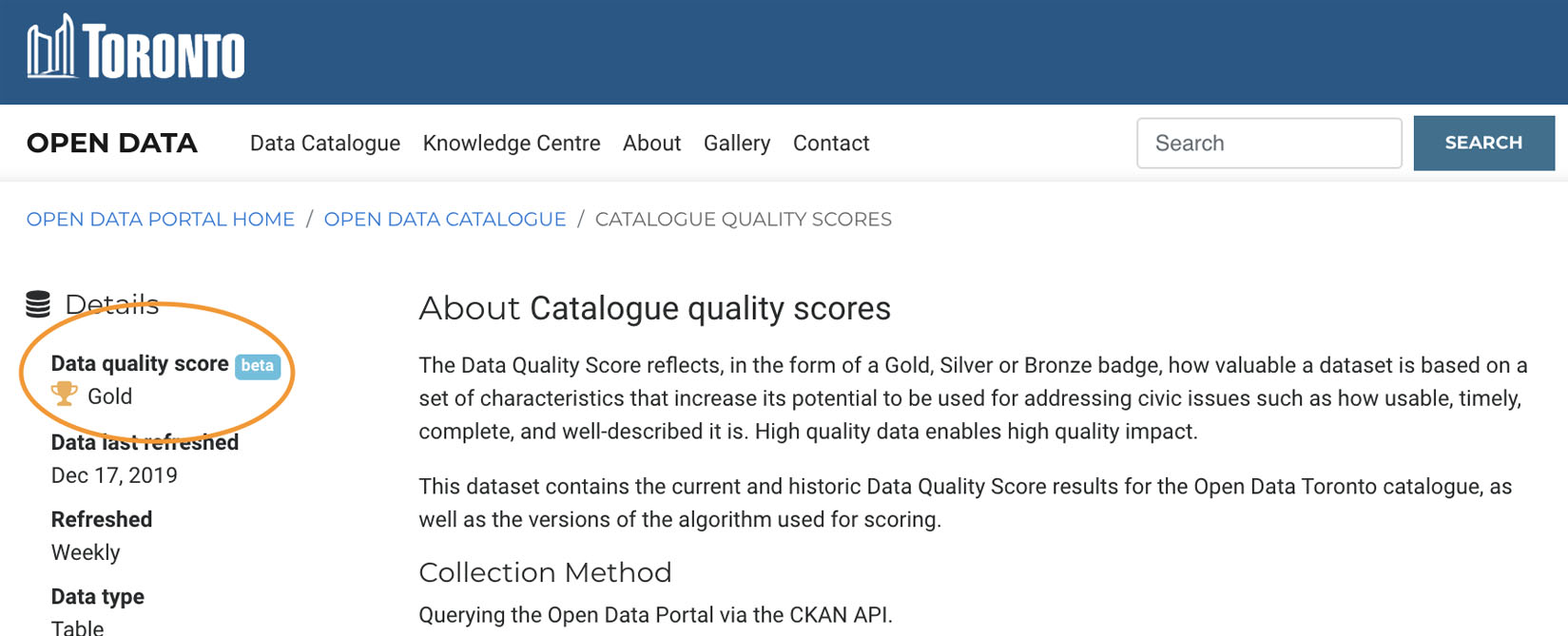
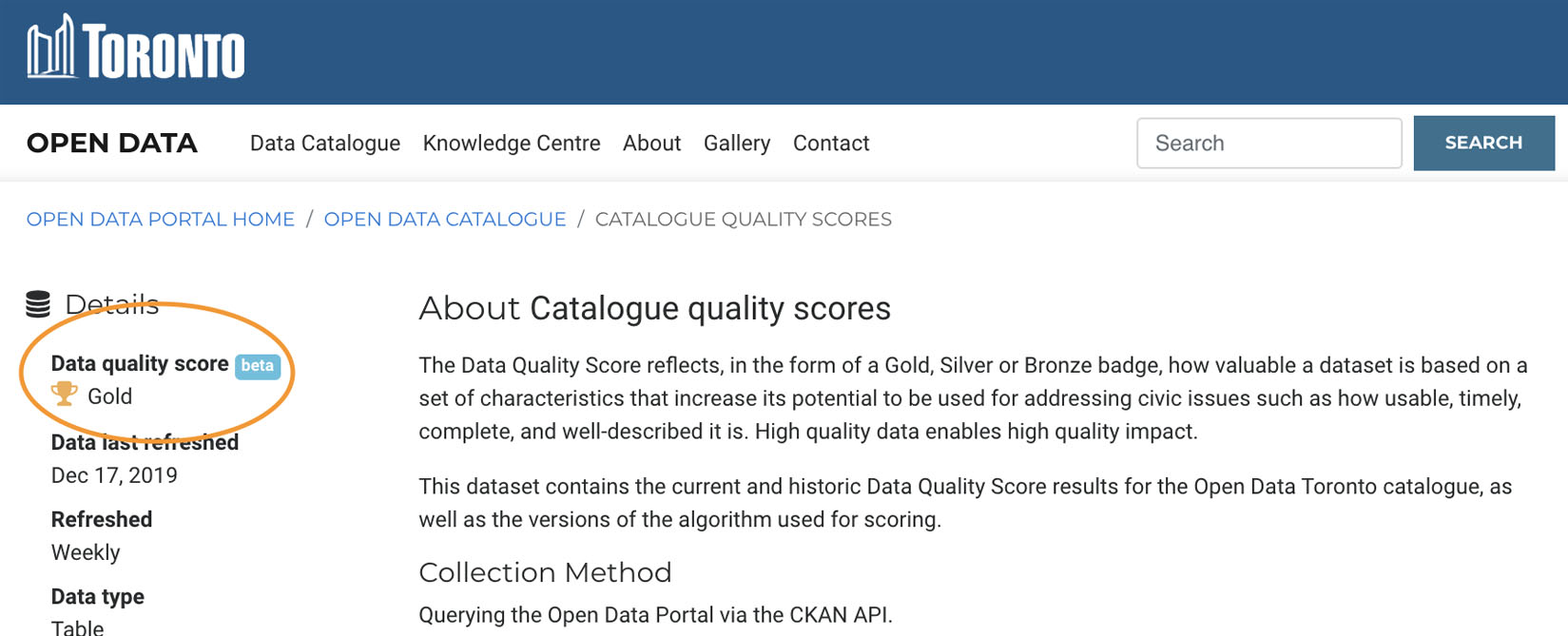 Data science can be complex! Simply providing data to our users doesn’t always solve their pain points, given that not all data sets are created equally. Data quality is integral to uptake, so we’ve introduced the Data Quality Framework.
The Data Quality Scoring Framework displays a Gold, Silver or Bronze badge per dataset, which helps measure the potential impact a dataset has to help address civic issues. A high quality dataset enables high quality impact, as it has the characteristics that makes it easy-to-use, comprehensive, timely, and relevant.
Data science can be complex! Simply providing data to our users doesn’t always solve their pain points, given that not all data sets are created equally. Data quality is integral to uptake, so we’ve introduced the Data Quality Framework.
The Data Quality Scoring Framework displays a Gold, Silver or Bronze badge per dataset, which helps measure the potential impact a dataset has to help address civic issues. A high quality dataset enables high quality impact, as it has the characteristics that makes it easy-to-use, comprehensive, timely, and relevant.
 Not a data scientist or API expert? Don’t have access to data analysis software? Not to worry. The new Google
Not a data scientist or API expert? Don’t have access to data analysis software? Not to worry. The new Google 


 The Toronto Open Data Team
The Toronto Open Data Team 






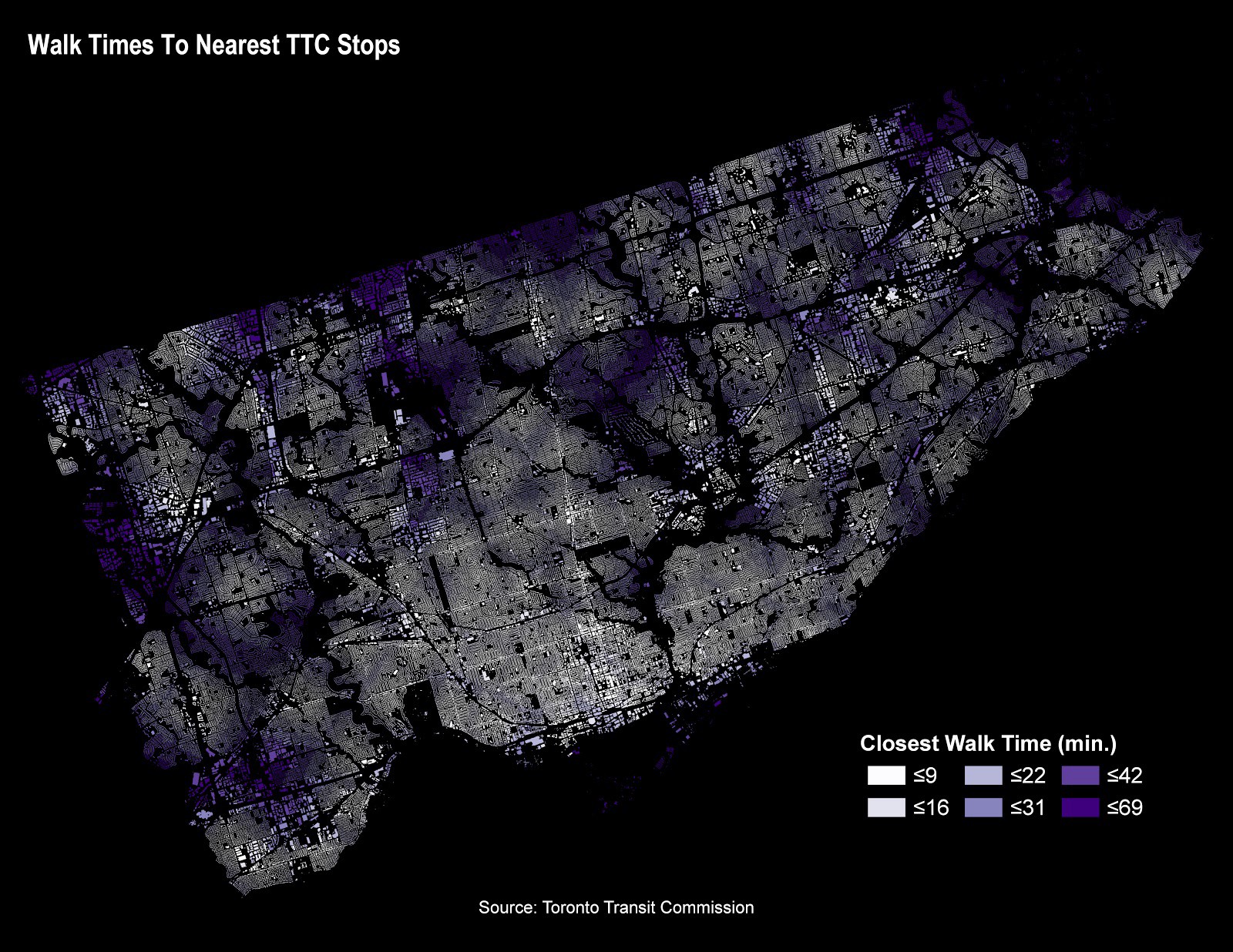 Read Measuring Walking Times Across Toronto to Nearest TTC Stop Using the Pedestrian Network and Python on Medium.
Read Measuring Walking Times Across Toronto to Nearest TTC Stop Using the Pedestrian Network and Python on Medium.

 A source system connection refers to how a user accesses a data source. There are many benefits to having a source system connection for your data instead of a static file (eg. Excel spreadsheet).
For one, the SSC serves as a “source of truth” for your data, so data stewards no longer need to update many different file types. Some datasets are very large and difficult to download efficiently. Others include more information than a user needs.
The open data team will help guide City data stewards who don’t already have an SSC to set one up for their open dataset.
A source system connection refers to how a user accesses a data source. There are many benefits to having a source system connection for your data instead of a static file (eg. Excel spreadsheet).
For one, the SSC serves as a “source of truth” for your data, so data stewards no longer need to update many different file types. Some datasets are very large and difficult to download efficiently. Others include more information than a user needs.
The open data team will help guide City data stewards who don’t already have an SSC to set one up for their open dataset.
 An open dataset must readily import into data visualization and analysis tools like Tableau or PowerBI. Examples of these open file formats include CSV, JSON, XML, and GeoJSON.
File format alone isn’t the only factor that make datasets machine readable. The structure of the dataset also has implications on the dataset’s readiness. The Open Data team will work with data stewards to improve the open data readiness of datasets to best make them machine readable.
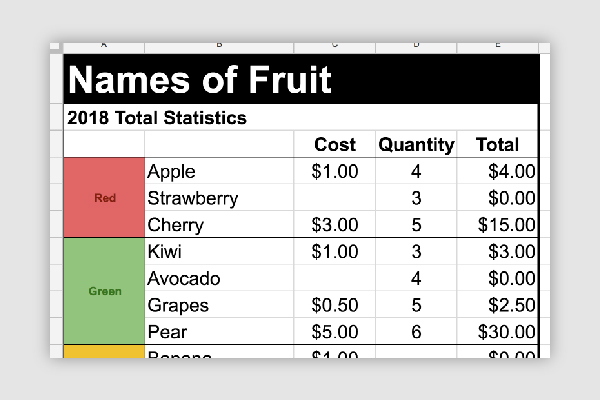
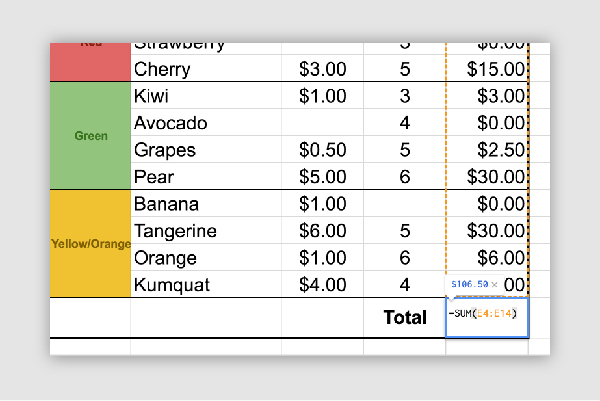
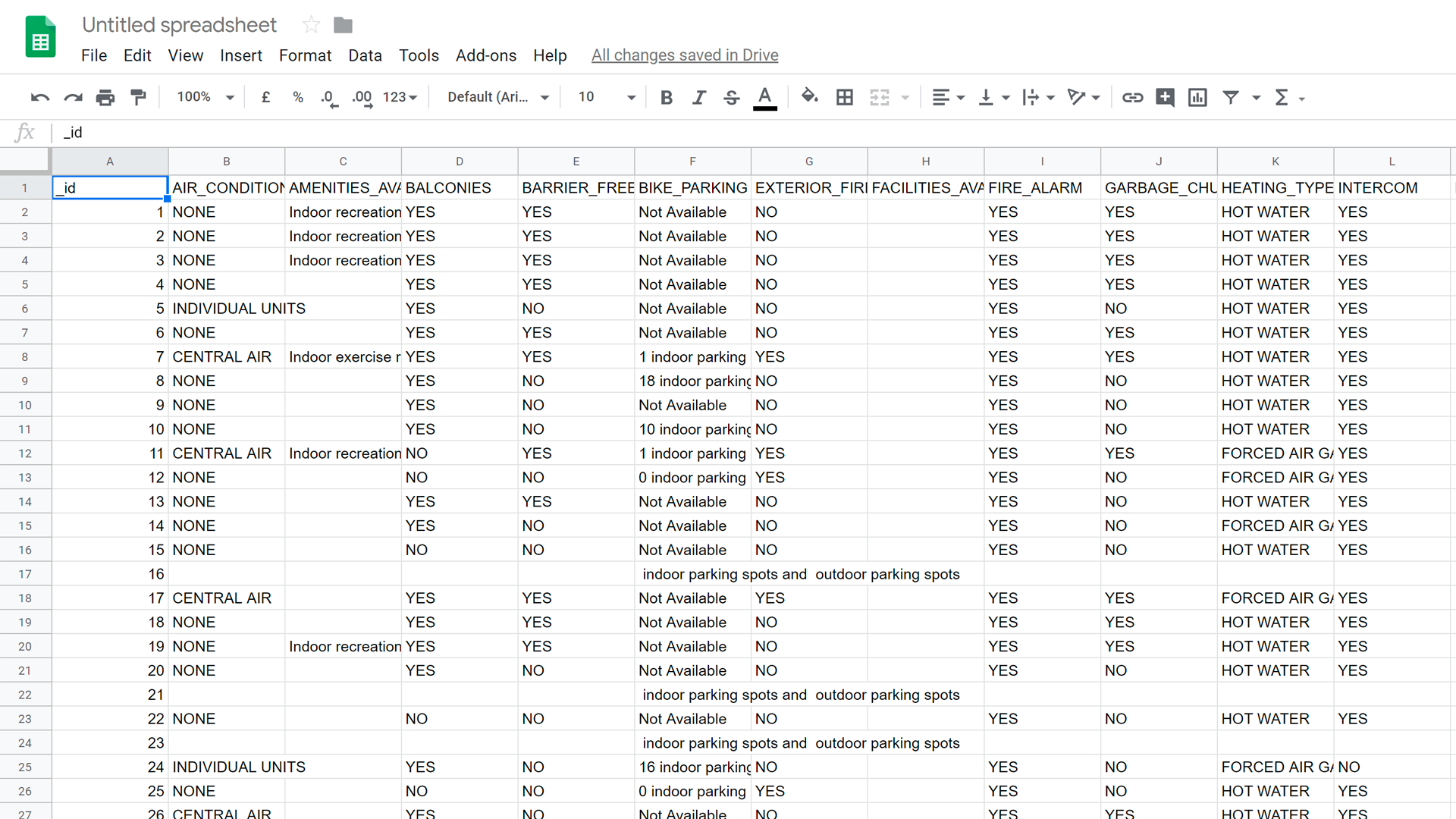
Structural improvements include removing merged cells, formulas, and summary data. Style elements like colours, font, and formatting should also be removed. They can in fact hinder the machine readability of your data.
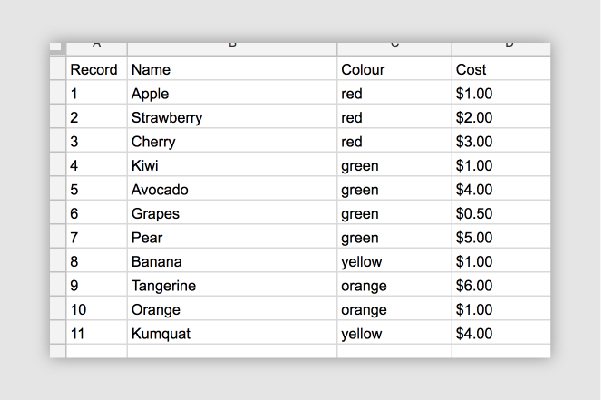
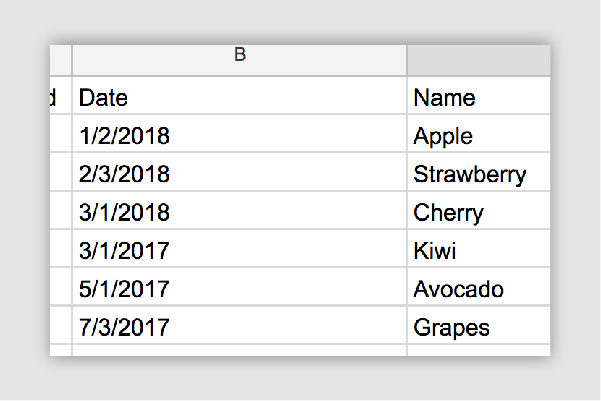
Formulas are also an important consideration. Open dataset files should be free of them. As a general rule, the first column of every row in a document should be a heading that describes the values in the column. Each row in a dataset should describe a single data entry.
An open dataset must readily import into data visualization and analysis tools like Tableau or PowerBI. Examples of these open file formats include CSV, JSON, XML, and GeoJSON.
File format alone isn’t the only factor that make datasets machine readable. The structure of the dataset also has implications on the dataset’s readiness. The Open Data team will work with data stewards to improve the open data readiness of datasets to best make them machine readable.
Structural improvements include removing merged cells, formulas, and summary data. Style elements like colours, font, and formatting should also be removed. They can in fact hinder the machine readability of your data.
Formulas are also an important consideration. Open dataset files should be free of them. As a general rule, the first column of every row in a document should be a heading that describes the values in the column. Each row in a dataset should describe a single data entry.
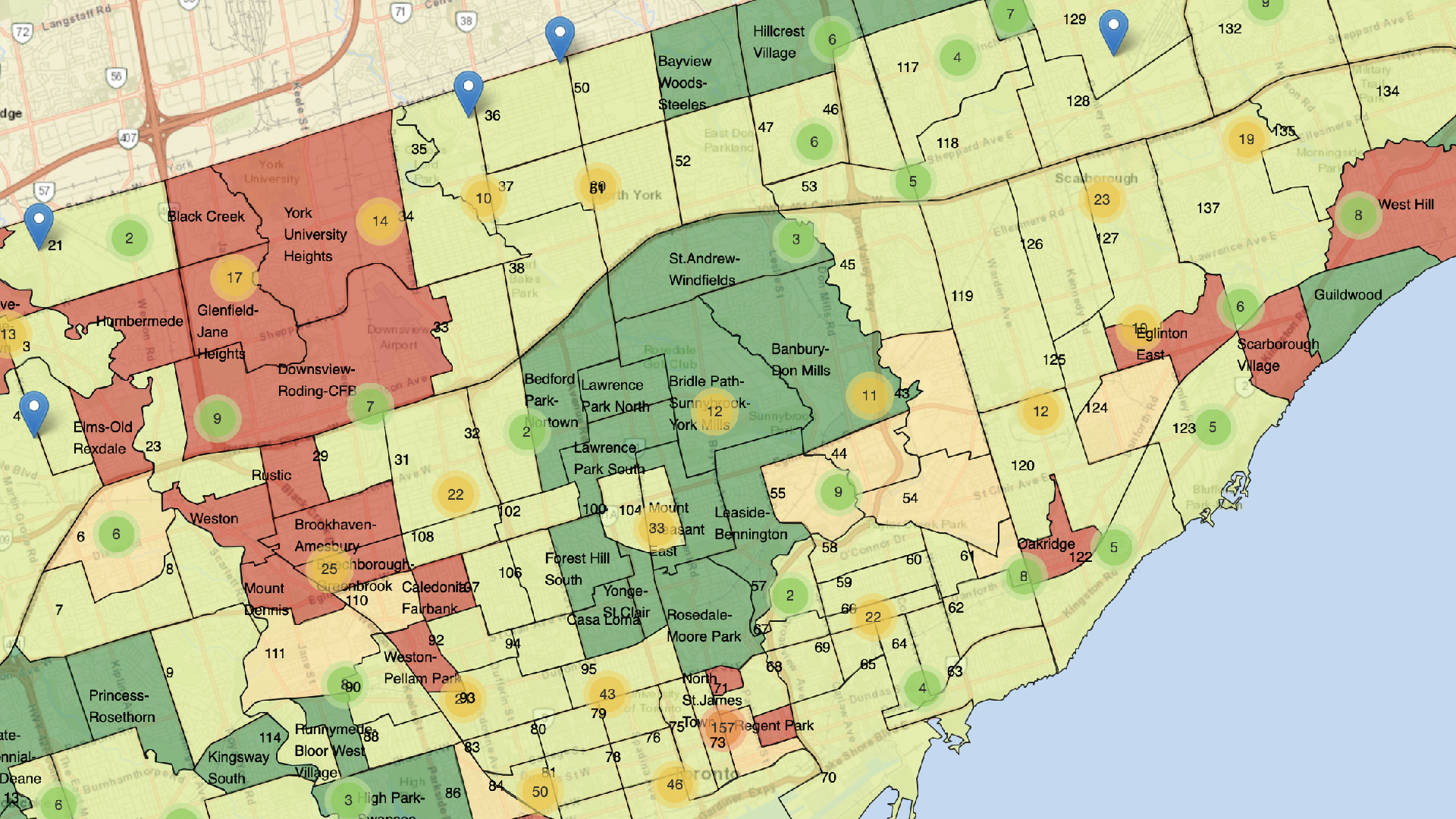
 We want to make sure that when data is requested, that data stewards are ready for it. By looking at site analytics, search terms, as well as current events, the Open Data team can get a general sense of how ‘in-demand’ a dataset is. Although a dataset may not have many hits on the Open Data portal doesn’t mean that it’s not important or relevant. We also consider requests for datasets as an important factor.
We want to make sure that when data is requested, that data stewards are ready for it. By looking at site analytics, search terms, as well as current events, the Open Data team can get a general sense of how ‘in-demand’ a dataset is. Although a dataset may not have many hits on the Open Data portal doesn’t mean that it’s not important or relevant. We also consider requests for datasets as an important factor.
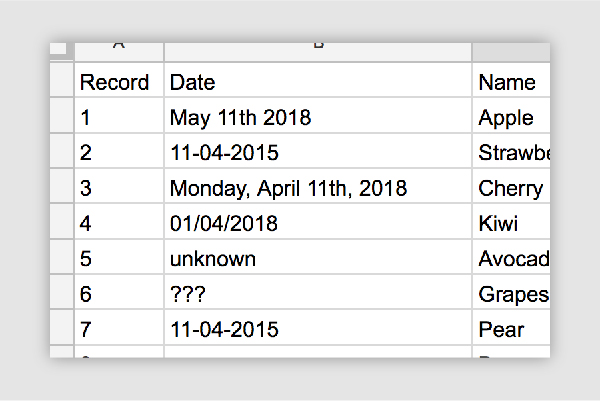
 Data freshness refers to not only how often a dataset is updated, but how accurately the metadata represents the refresh rate. For example, if a dataset says that it is updated on a weekly basis, but the last data entry was 8 months ago, the dataset would have a lower rating.
Please note that it is possible for some datasets to be updated less consistently by design. An example is a survey or evaluation that occur every 10 years. Regardless, it’s important to ensure that metadata correctly represents how often a user can expect to see updates.
Data freshness refers to not only how often a dataset is updated, but how accurately the metadata represents the refresh rate. For example, if a dataset says that it is updated on a weekly basis, but the last data entry was 8 months ago, the dataset would have a lower rating.
Please note that it is possible for some datasets to be updated less consistently by design. An example is a survey or evaluation that occur every 10 years. Regardless, it’s important to ensure that metadata correctly represents how often a user can expect to see updates.
 Data should always aim to be as detailed as possible. Data should be non-aggregated and only provide raw values. This will allow users to visualize and analyze the data as they need. When raw data is provided. as opposed to summary data (e.g. totals), this makes it easy for users to use the data in innovative and creative ways.
Aggregated data may be provided on a case-by-case basis. This would include situations where it is impossible to report on granularity for privacy, technical, or legal reasons.
Data should always aim to be as detailed as possible. Data should be non-aggregated and only provide raw values. This will allow users to visualize and analyze the data as they need. When raw data is provided. as opposed to summary data (e.g. totals), this makes it easy for users to use the data in innovative and creative ways.
Aggregated data may be provided on a case-by-case basis. This would include situations where it is impossible to report on granularity for privacy, technical, or legal reasons.
 A majority of the current open data catalogue is only available in proprietary formats. Proprietary formats, such as Excel Spreadsheets, are file types that are the property of a particular software company like Microsoft. This limits who can access the data, as the end user typically requires a paid software license to open these files. In some cases, the files may not render correctly in visualization tools. Luckily, there are many universal open formats that can be substituted that do not require special software to open or access, such as CSV. That’s why we will be moving to publishing in open formats only.
A majority of the current open data catalogue is only available in proprietary formats. Proprietary formats, such as Excel Spreadsheets, are file types that are the property of a particular software company like Microsoft. This limits who can access the data, as the end user typically requires a paid software license to open these files. In some cases, the files may not render correctly in visualization tools. Luckily, there are many universal open formats that can be substituted that do not require special software to open or access, such as CSV. That’s why we will be moving to publishing in open formats only.