
rideTO was designed for regular TTC commuters who already know the routes, stops, and stations they use most often.
The core pain point was not discovering how to travel from point A to point B. It was the daily friction of piecing together a reliable picture of their commute from multiple sources: checking one app for next arrivals, X for updated service alerts, and the TTC website for planned closures. That fragmented experience added cognitive load to something commuters needed to do quickly, often while already on the move.
The product strategy focused on one question: how can a commuter absorb the status of their regular TTC trip quickly, accurately, and with less effort, in a single place?
The answer was to unify the experience. Rather than sending riders across different apps and sources, rideTO brings next arrivals, route alerts, subway status, scheduled closures, accessibility outages, and more into one coherent view built around the stops and routes each commuter already knows.
This article covers the product decisions, data sources, and design tradeoffs that shaped rideTO and what it looks like when Toronto Open Data becomes a daily commuter tool.
Product Boundary: Commute Support, Not Route Planning
rideTO is intentionally not a point A-to-B trip planner. It does not generate connecting routes or recommend full itineraries.
Instead, it supports people who already understand their TTC patterns and want a faster way to monitor the services they use regularly.

Scannability as the Core UX Principle
Transit information is often consumed under pressure: while walking to a stop, standing on a platform, transferring, checking a phone outdoors, or making a quick decision before leaving home.
For rideTO, scannability is not a visual preference. It is a product requirement.
Each major feature was designed to reduce the amount of cognitive work needed to understand what is happening on screen.

Open Data Strategy
rideTO uses TTC(Toronto Transit Commission) open data as the structural foundation for commute support.
The app draws on TTC route, stop, and schedule data published through the Toronto Open Data TTC routes and schedules dataset. This data helps define the network: route identity, stop identity, stop locations, route-stop relationships, and schedule context.
That foundation is combined with official TTC operational sources: real-time service alerts from the TTC Service Alerts feed, live arrival predictions from the NextBus API, real-time vehicle and trip updates from the TTC GTFS Realtime dataset, and additional data covering scheduled closures, accessibility outages, subway status, slow zones, and service-resumed notices.

The design value comes from turning available data into a coherent screen-level experience that matches commuter habits. Open data impact depends on how well public information is shaped for public use. That shaping is where the product decisions matter.
Accessibility by Design
Accessibility was prioritized across the app, both in content and interface behaviour.
rideTO surfaces elevator and escalator outages because they directly affect whether some riders can complete a regular trip. But accessibility also shaped the broader interface system.
Implemented accessibility-supporting choices include:
- Lexend typography, a font designed to improve readability and support users with dyslexia
- French translation, so more Toronto riders can use the app in their preferred official language
- Motion reduction options, supporting users who prefer reduced animation
- Theme preference, allowing users to choose a visual mode that is more comfortable for them
- Progressive web app installation, making the app available from the home screen on iOS and Android
These choices make the product more usable for a broader range of riders, while reinforcing the open-data goal of public access.
Service Blueprint
rideTO can be understood as a commuter information service with frontend and backstage layers.

Strategic Tradeoffs
Several tradeoffs shaped the product direction.

These tradeoffs kept rideTO focused on commuter comprehension, accessibility, and practical public value.
Recognition
rideTO won the Canadian Open Data Accessibility Award 2025 from the Canadian Open Data Society, recognizing its use of open data to improve access to transit information for the public.

Closing Thought
The promise of open data is not only that information exists in public. It is that public information can become easier to use in real life.
rideTO was designed for daily TTC riders who already know their commute and need quick, clear answers. Through scannable feature design, accessibility-first choices, and saved commuter context, the app aims to help riders absorb transit information with less effort and greater confidence. Try rideTO at rideto.ca.




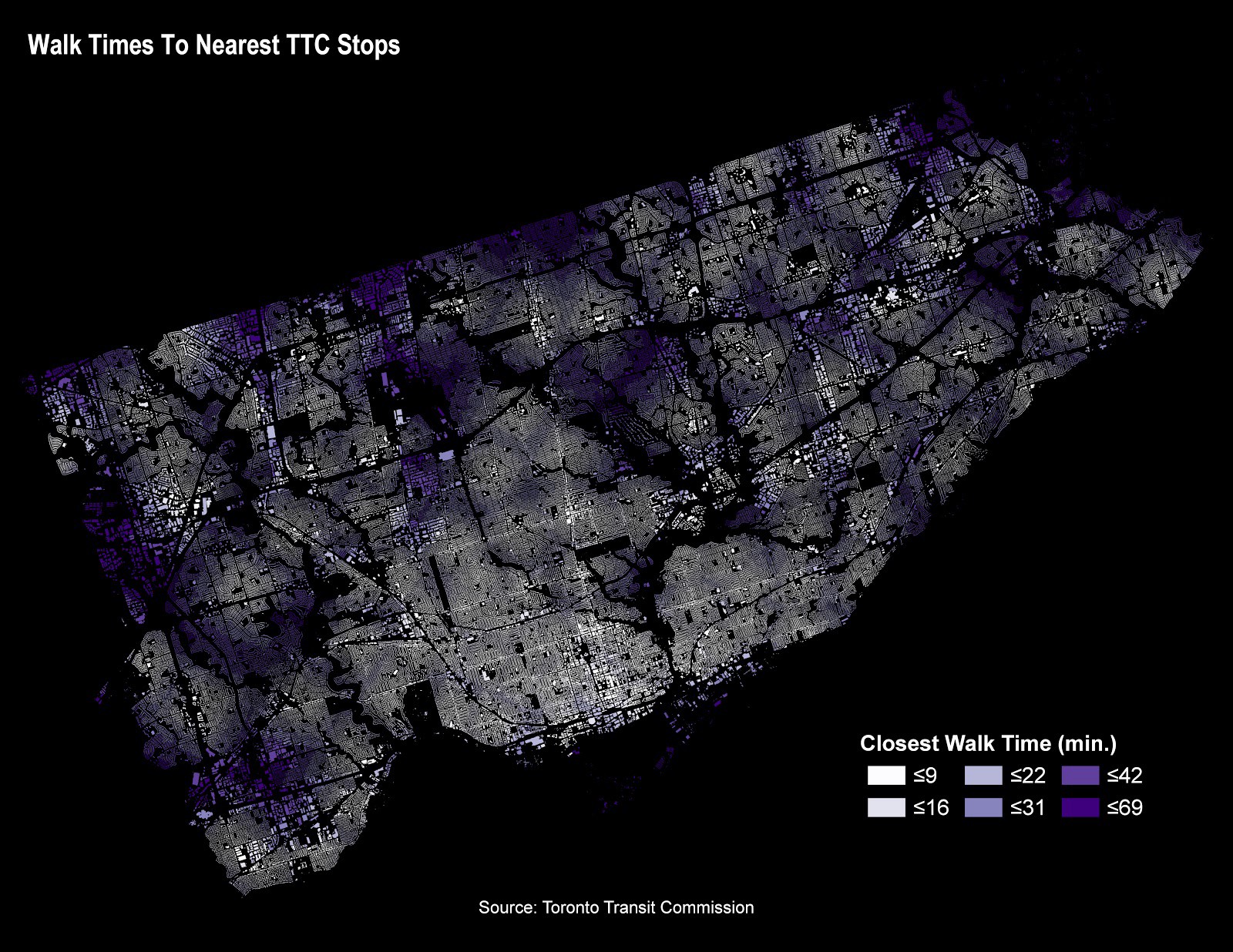 Read Measuring Walking Times Across Toronto to Nearest TTC Stop Using the Pedestrian Network and Python on Medium.
Read Measuring Walking Times Across Toronto to Nearest TTC Stop Using the Pedestrian Network and Python on Medium.
 Read the full article on Medium.
Read the full article on Medium.
