
A great example, partnership and arguably a great use-case of how open data is used in big Cities. One of our key collaborators in this endeavor is UrbanToronto, a comprehensive resource for tracking new developments across the Greater Toronto Area.
This blog post delves into our successful partnership with UrbanToronto, highlighting how our open data fuels their innovative services and how, together, we are helping citizens and professionals alike see the future of our city through data. Written by UrbanToronto.
If you ever search for a new condo development, you’ll likely come across UrbanToronto. We track every large new project in the GTA (and beyond) in four different ways: a quantitative database page for the project; a discussion thread in our highly active discussion forum; a pin on our detailed map; a news story about the project written by one of our journalists.
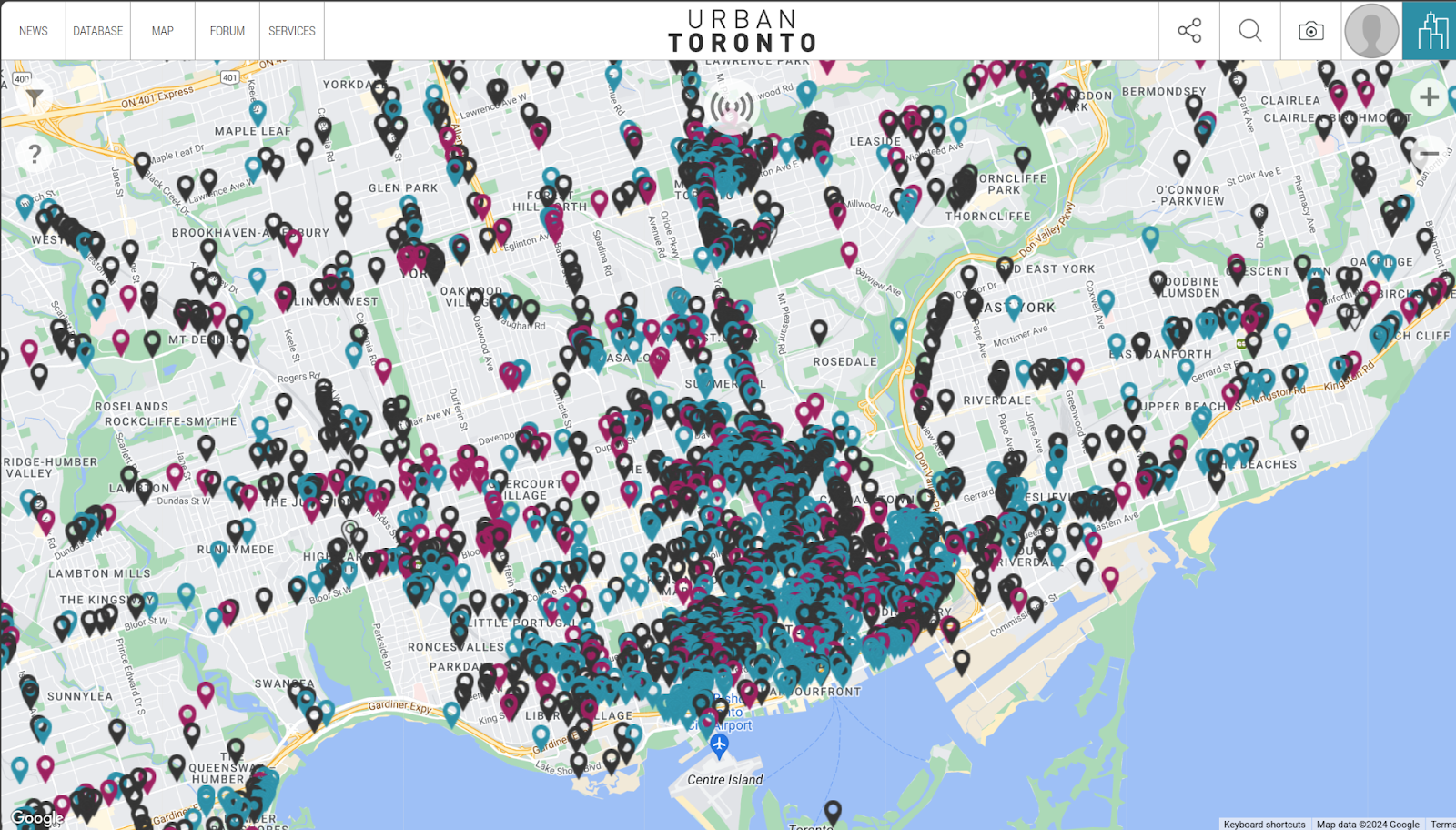
All four of these information services rely heavily on open data from the City of Toronto. We transform this data into a standardized format to allow searching, filtering, and plotting, which fuels the rest of the services we offer.
While our business is predominantly based on data today, it wasn’t always the case. Here is the story of how open data transformed UrbanToronto’s business.
History of UrbanToronto
You know how there are train geeks, movie geeks, and history geeks—people who love to learn and talk about these topics in great detail?
Skyscraper geeks exist, too: people who love to talk about the newest high rise developments in the city. But unlike most discussions on TV or the newspapers about condos, skyscraper geeks don’t care so much about prices. Instead, they would focus on the design of the building, the construction process, and the urban planning involved.
UrbanToronto began more than 20 years ago as a discussion forum for skyscraper geeks in Toronto. Much like the city we cover, our business has grown a lot in that time, too.
Soon after the forum started taking off, we added a news component to the website. We cover breaking news in the development industry, as well as feature articles highlighting new technologies, new policies, and innovative builders, suppliers, and designers in the field.
Our Data Origin Story
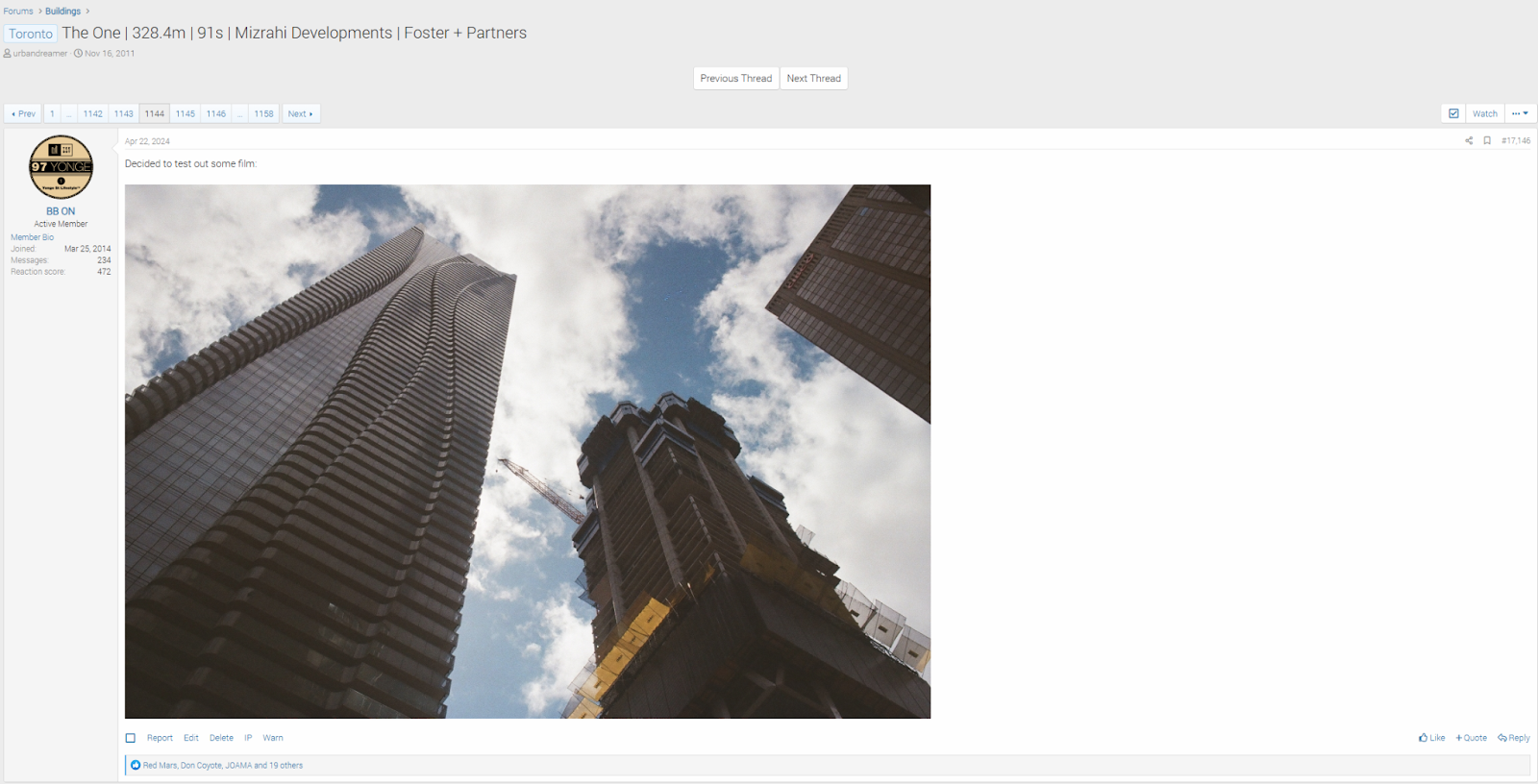
As the popularity of our community grew, so did the needs of our forum members and journalists. We have thousands of threads for individual projects, and some have hundreds of pages of comments with thousands of posts. The posts include construction photos, but also images of the architectural plans, and other data about the project. If you wanted to know how tall a building was, but there were 300 posts into the discussion, you would struggle to find the information.
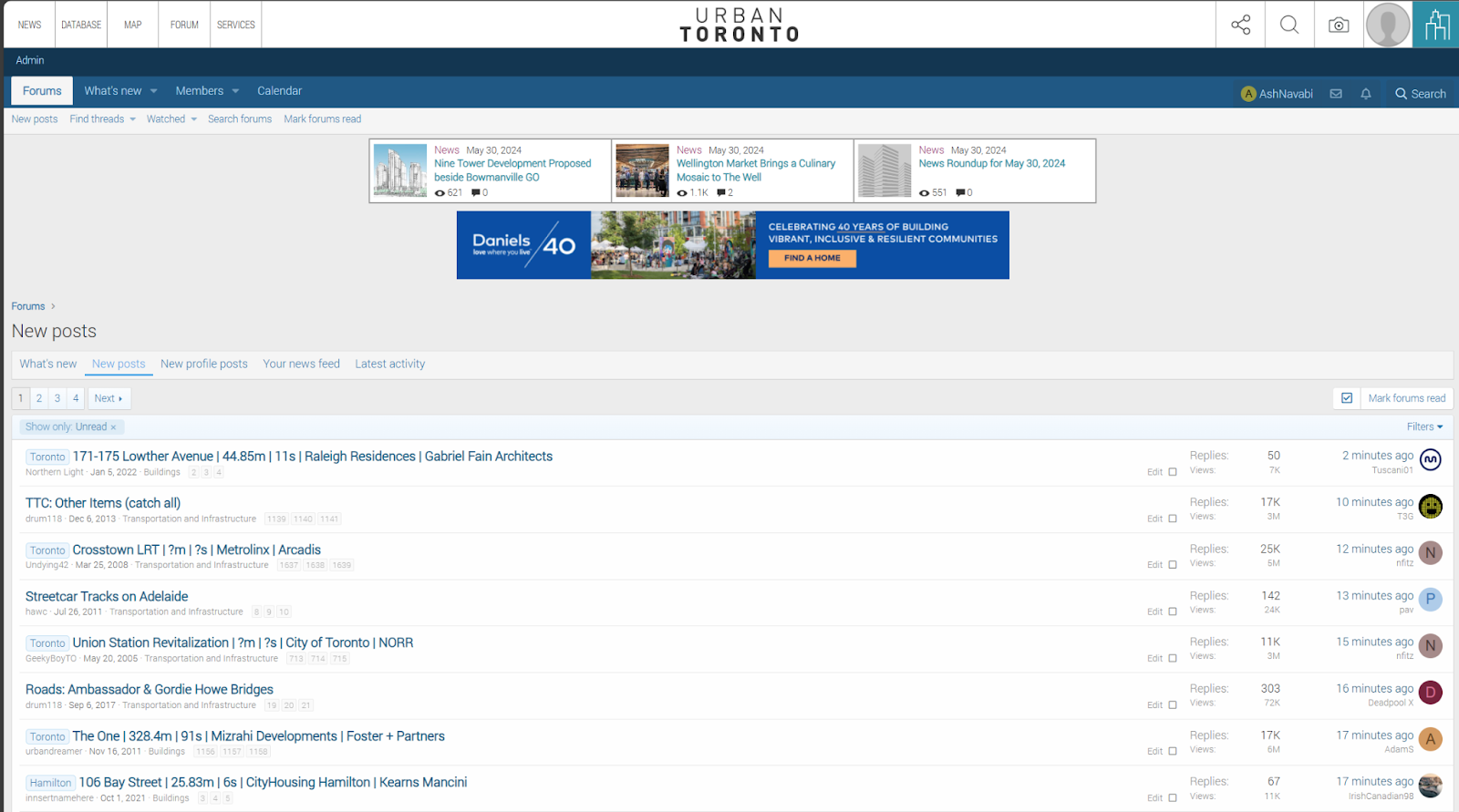
Enter the UrbanToronto database, version 1.0. Especially popular projects got a dedicated page that listed their crucial information: some renderings, the heights, unit mix, and the developer and architect. All of this data came from City of Toronto planning documents. What’s more is that we also started plotting these projects on a map, colour-coded by construction status. That way, you could see where the big projects in the city were going up.
Soon enough, this database grew to over a thousand projects. At this point, the database itself, and especially the map that was built on top of it, had grown a dedicated user base of their own. We realized it made sense to invest more into our map and database service, which involved hiring a bigger team, investing in new technologies, and expanding the scope and depth of our data.
Today, UrbanToronto data is available for free, as well as a premium subscription package called UTPro. We track over 5000 projects across the Greater Golden Horseshoe, although due to the City of Toronto’s excellent open data products, our coverage in Toronto is the deepest and most accurate.
What Data Does UrbanToronto Track?
Unlike other real estate data providers, we rely almost exclusively on publicly available documents. While we track a wide variety of sources, including building permits and the heritage registry, our main source of data are development applications: rezoning, site plan approvals, Official Plan amendments, and so on.
There is a vast wealth of information in these applications, and many people and organizations link to and track them. However, they can comprise 60 different documents, most of which are in PDF format. This lowers the digital legibility of the documents, which is where UrbanToronto comes in. Through a combination of manual and automated processes, we read every one one of those PDF and input the data into a standardized format which makes filtering, sorting, and plotting the data much easier.
Our data is used by three types of users: (1) those looking to buy or develop new properties, including developers, urban planners, land assemblers, and retail condo investors; (2) realtors, tradespeople, and suppliers looking for leads on new developments and projects under construction; and (3) thousands of enthusiasts who, for their own interests, consult our map and database to stay up to date with what’s going on in their neighbourhood.
The Future for UrbanToronto and Open Data
While we are constantly expanding our database with new projects (as well as updating existing projects), our focus has historically been on “large” developments—typically townhouses and above. As the City is changing policy to permit more infill development, our database will be expanding to include these smaller projects as well. We are also in the process of expanding the features of our map to include more functionality in terms of filtering and exporting the data, as well as new layers to supplement the investment decision processes.
We’re looking forward to continuing to build our relationship with the City’s Open Data team, as we deepen our coverage of development in Toronto.

